Make教程:用Make打造信达雅反思翻译工作流,告别AI翻译腔
结合OpenRouter多模型切换、Jina Reader PDF提取和反思审校机制,实现高质量PDF自动翻译,支持自定义术语表和文本分段。
准备好开始自动化了吗?
使用 Make.com 构建此工作流 — 入门版永久免费。
概述
这是一套追求翻译质量的高阶自动化方案。
通过引入”信达雅”反思机制,让AI翻译告别生硬的机翻腔:
- PDF提取 - Jina Reader转换为Markdown
- 智能分段 - Repeater按设定粒度切分
- 初稿翻译 - AI生成第一版译文
- 反思审校 - 基于信达雅原则提出改进建议
- 生成定稿 - 融合建议输出高质量译文
- 结果保存 - 回写Notion数据库
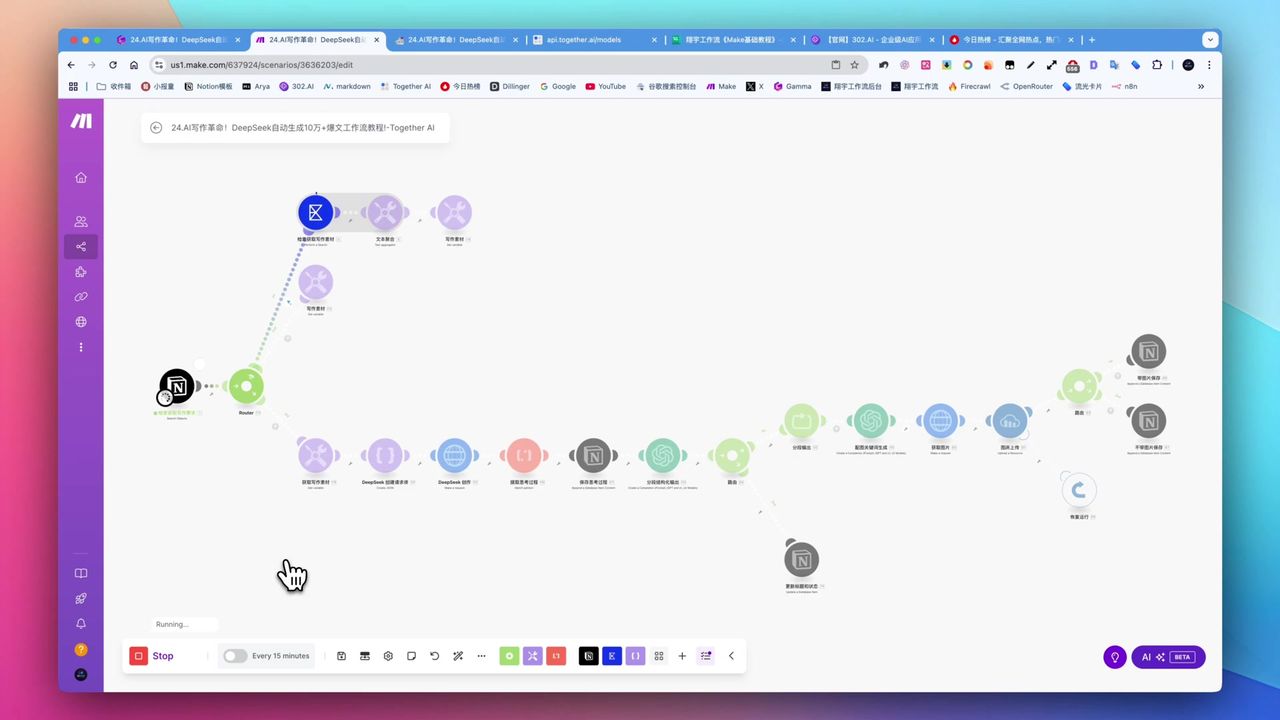
 PDF反思翻译自动化工作流架构
PDF反思翻译自动化工作流架构
核心决策因素
在选择AI翻译方案时,需重点考量:
- 翻译质量 - 能否达到”信、达、雅”标准,避免直译
- 模型灵活性 - 能否根据任务切换不同AI模型
- 文本处理能力 - 对长文本的分段和格式处理
- 自定义能力 - 是否支持术语表和语言对设置
- 成本效益 - 在保证质量前提下的性价比
技术规格参考
| 规格项 | 参数值 | 备注 |
|---|---|---|
| 支持AI模型 | GPT-4o Mini, Claude, Gemini等 | 通过OpenRouter切换 |
| 文本分段粒度 | 100/300/600/1000字符 | 可根据需求调整 |
| Notion PDF限制 | 5MB | 免费账户,可压缩处理 |
| Notion文本限制 | 2000字符 | 需分段或Append保存 |
| PDF提取API | Jina Reader | 近似免费 |
| GPT-4o Mini成本 | 百万Token不到10元 | 性价比极高 |
前置准备
在开始之前,请确保准备好:
- Make.com 账号(免费注册)
- OpenRouter API密钥(支持多模型)
- Jina Reader API密钥(PDF提取)
- Notion 账号和数据库
Notion数据库结构
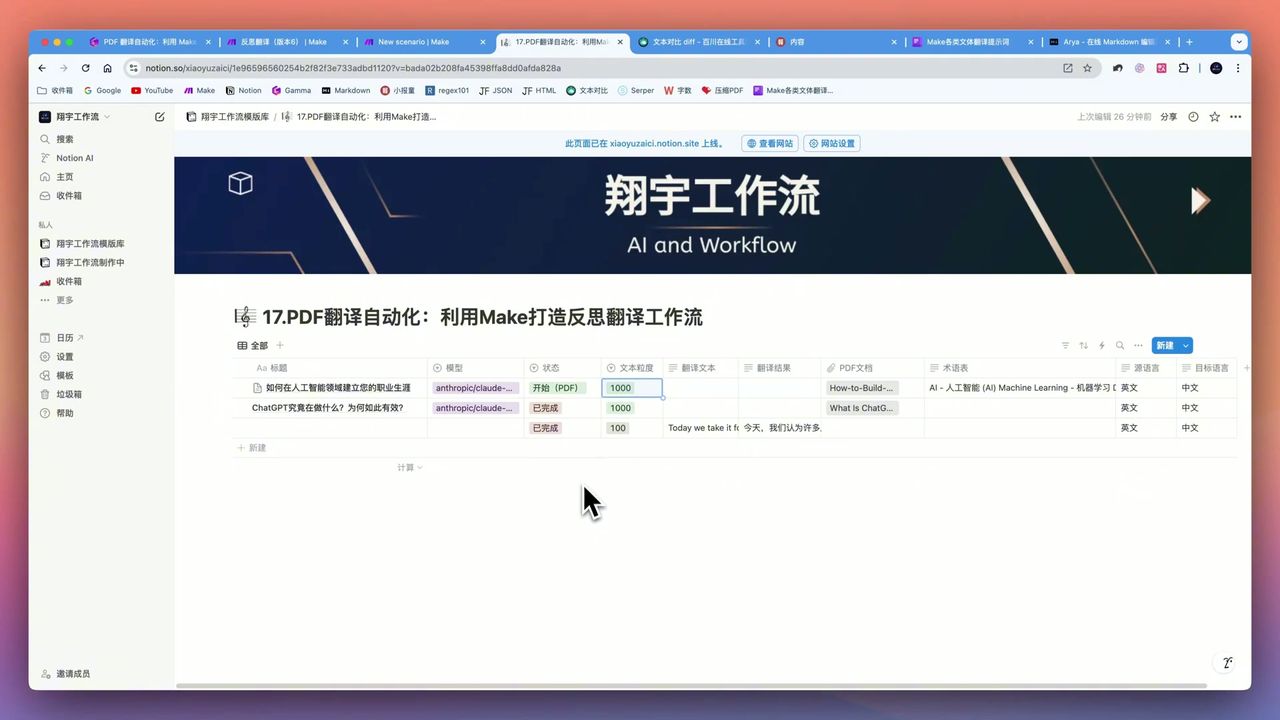 数据库属性设置
数据库属性设置
创建翻译任务数据库,包含以下字段:
- 状态 (Select) - 待处理/处理中/已完成
- 模型选择 (Select) - GPT-4o Mini/Claude/Gemini
- 文本粒度 (Select) - 100/300/600/1000
- 源语言 (Select) - 英语/日语/法语等
- 目标语言 (Select) - 中文/英语等
- 术语表 (Text) - 自定义专业术语
- PDF文件 (Files) - 待翻译文档
- 翻译结果 (Text) - 输出译文
工作流架构
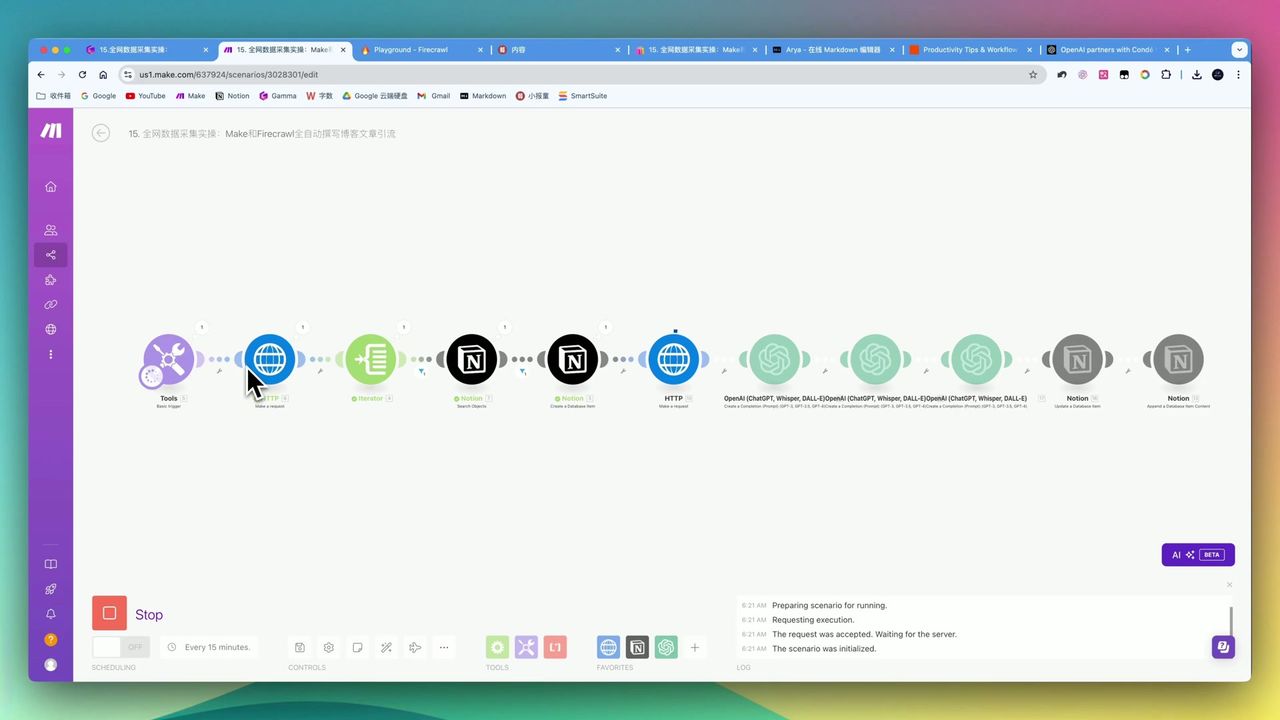
阶段一:PDF提取
使用Jina Reader将PDF转换为Markdown:
配置要点:
- API近似免费
- 输出Markdown格式
- 保留文档结构
注意:配置API Key时确保凭证正确,否则会出现401错误。
阶段二:智能分段
 文本分段公式设置
文本分段公式设置
使用Repeater模块进行长文本分段:
分段逻辑:
- 根据用户设置的粒度(如1000字符)
- 使用Substring函数动态切分
- 计算总段数:文本长度 / 粒度
为什么要分段?
- 避免超出模型Token限制
- 提高翻译准确性
- 便于逐段审校
阶段三:初稿翻译
调用AI模型生成第一版译文:
Prompt设计要点:
你是一位专业翻译,精通{{source_lang}}和{{target_lang}}。
请将以下文本翻译成{{target_lang}}:
- 保持原文含义的准确性
- 使用自然流畅的表达
- 参考术语表:{{glossary}}
原文:
{{text_segment}}阶段四:反思审校(核心创新)
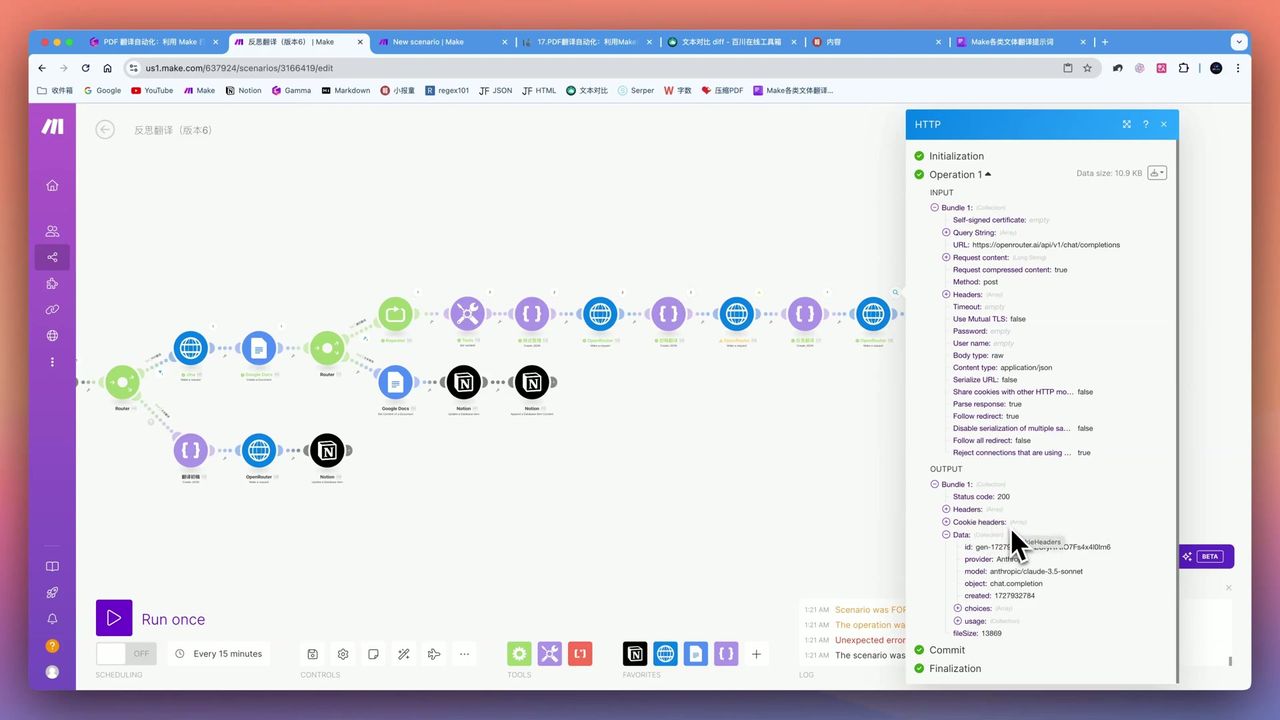 原文、改进译文及建议对比
原文、改进译文及建议对比
这是本工作流的核心亮点——基于”信达雅”原则的反思机制:
反思Prompt设计:
你是翻译质量审核专家,请基于"信、达、雅"原则审阅以下译文:
- 信:是否准确传达原文含义
- 达:是否通顺流畅,符合目标语言习惯
- 雅:是否优美得体,避免生硬翻译腔
原文:{{original}}
译文:{{translation}}
请提出{{suggestion_count}}条具体改进建议。建议数量计算:
- 1000字符文本:约26条建议
- 100字符文本:约5-7条建议
- 公式:文本粒度 / 50 + 6
警告:不要盲目要求过多建议(如100条),会导致AI产生幻觉,给出无意义的建议。
阶段五:生成定稿
 反思翻译带来的质量提升
反思翻译带来的质量提升
融合审校建议生成最终译文:
效果对比:
- “打造” vs “构建”
- “AI编程” vs “编写AI代码”
- 更自然、更有”人味儿”
注意事项
在实操中容易遇到的”坑”:
-
长文档耗时 - 完整翻译长文档需要较长时间,可能需要数十分钟
-
Notion限制 - PDF限制5MB,文本属性限制2000字符
-
JSON格式问题 - 文本中的双引号等特殊字符可能破坏JSON结构
-
API授权错误 - 确保API Key配置正确,避免401错误
-
建议数量控制 - 过多建议会导致AI幻觉,需要合理设置
适用场景
推荐使用的用户
- 专业翻译人员 - 需要高质量翻译且处理大量PDF文档
- 内容创作者 - 需要去除”AI味儿”的润色翻译
- 跨国企业/研究人员 - 需要翻译内部文档和研究报告
可能不适合的情况
- 对Make.com和API配置完全不熟悉的零基础用户
- 只需偶尔简单翻译的普通用户
- 对翻译时效性有极致要求的场景
常见问题
什么是反思翻译?
反思翻译是在初稿翻译后,让AI基于”信达雅”原则进行自我审阅并提出改进建议,最终生成更高质量的定稿,有效去除AI翻译腔。
为什么要用OpenRouter?
OpenRouter支持多模型切换,可以根据任务选择不同模型:简单任务用GPT-4o Mini省钱,高要求任务用Claude提升质量。
长文本如何处理?
使用Repeater模块结合Substring函数进行智能分段,支持100/300/600/1000字符等粒度,避免超出Token限制。
Notion有什么限制?
免费账户PDF上传限制5MB,文本属性限制2000字符。大PDF需压缩,长文本需分段或用Append模块保存。
下一步
学会了基础工作流后,你可以尝试:
- 添加更多语言对支持
- 集成专业术语库
- 添加翻译记忆功能
- 输出到Google Docs保存
有问题欢迎在评论区留言交流!
常见问题
- 什么是反思翻译?
- 反思翻译是在初稿翻译后,让AI基于'信达雅'原则进行自我审阅并提出改进建议,最终生成更高质量的定稿,有效去除AI翻译腔。
- 为什么要用OpenRouter?
- OpenRouter支持多模型切换,可以根据任务选择不同模型:简单任务用GPT-4o Mini省钱,高要求任务用Claude提升质量。
- 长文本如何处理?
- 使用Repeater模块结合Substring函数进行智能分段,支持100/300/600/1000字符等粒度,避免超出Token限制。
- Notion有什么限制?
- 免费账户PDF上传限制5MB,文本属性限制2000字符。大PDF需压缩,长文本需分段或用Append模块保存。